PDS Data Optimization by LLM AI
The Planning, Urban Design and Sustainability (PDS) department struggled to manage over 500 consequential amendments and digitize policy PDF files, facing a significant challenge in keeping up with changes. Every by-law or regulation change triggered a large amount of manual amendment, requiring staff to wade through hundreds of PDFs, search for references, and revise them one by one - a monumental task that hindered efficiency and accuracy.

SOLUTIONS
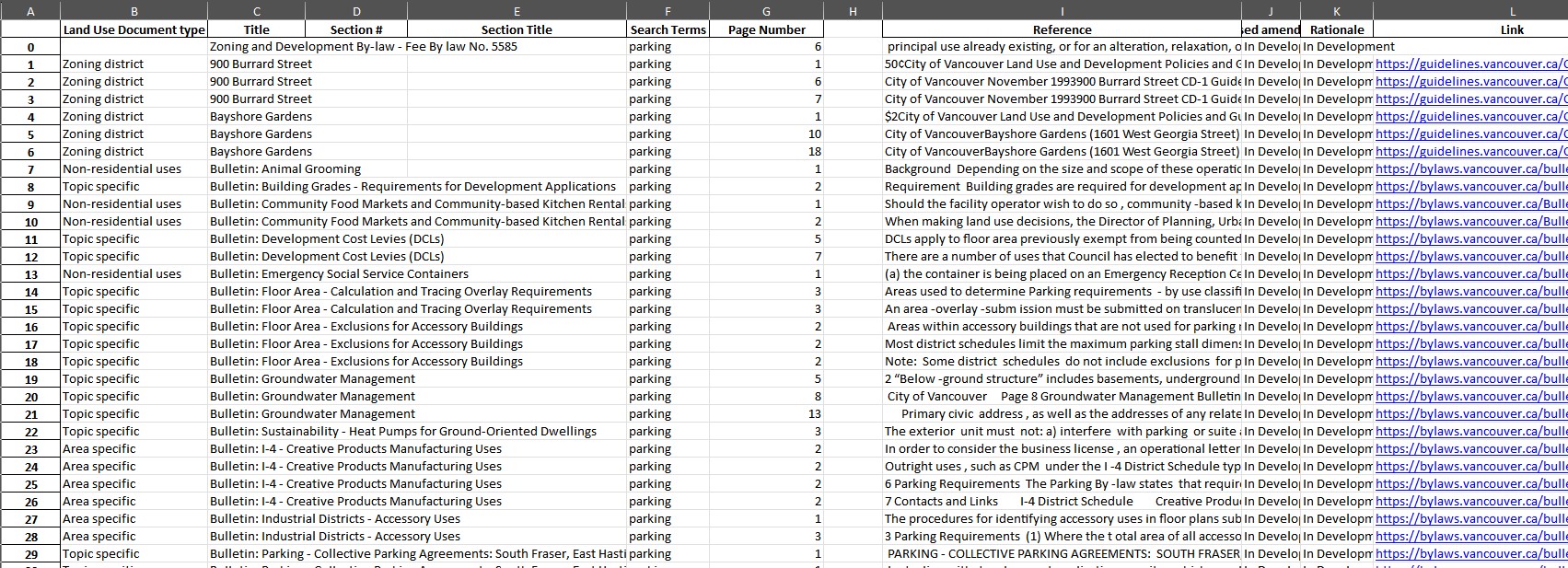
- Generative AI - Integrated an LLM AI model to analyze over 500 landscape documents, extracting key metrics information with over 90% accuracy.
- Next.js/Python Full-Stack App - Generates suggestions for editing or replacing analyzed information; Automates report creation, reducing manual workload from weeks to less than 5 minutes.
- Web Scraping - Automated the document download and update process by sophisticated web scraping techniques, significantly reducing manual retrieval time.
PROJECT DETAILS
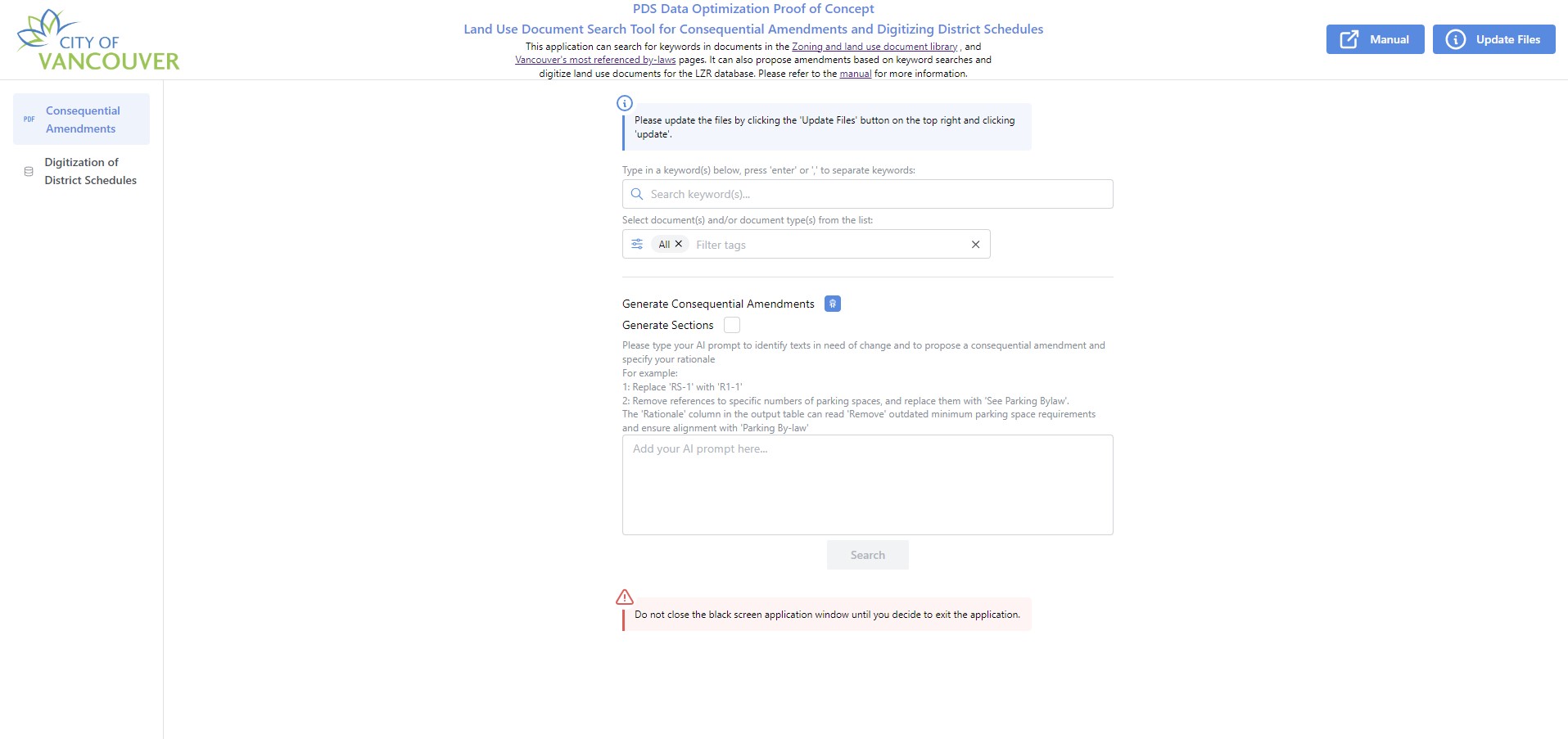
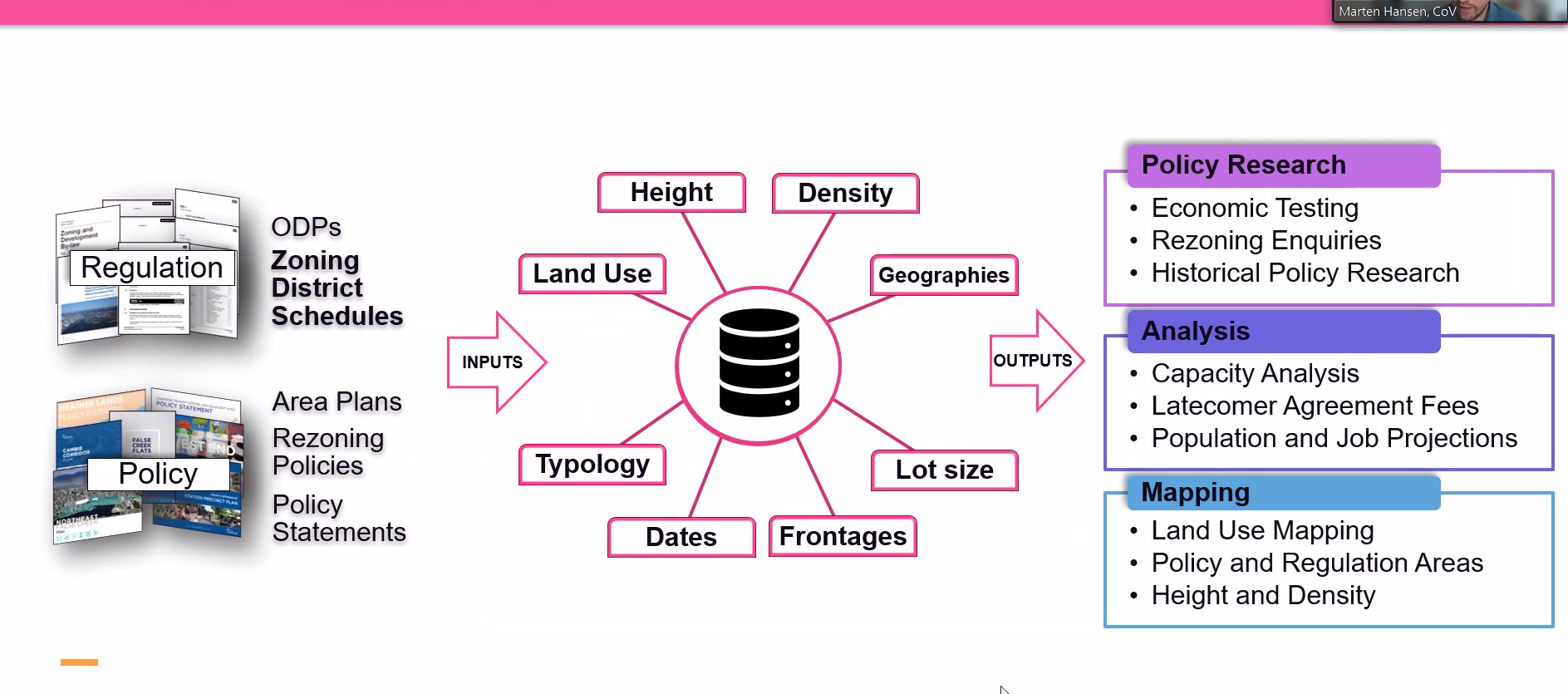
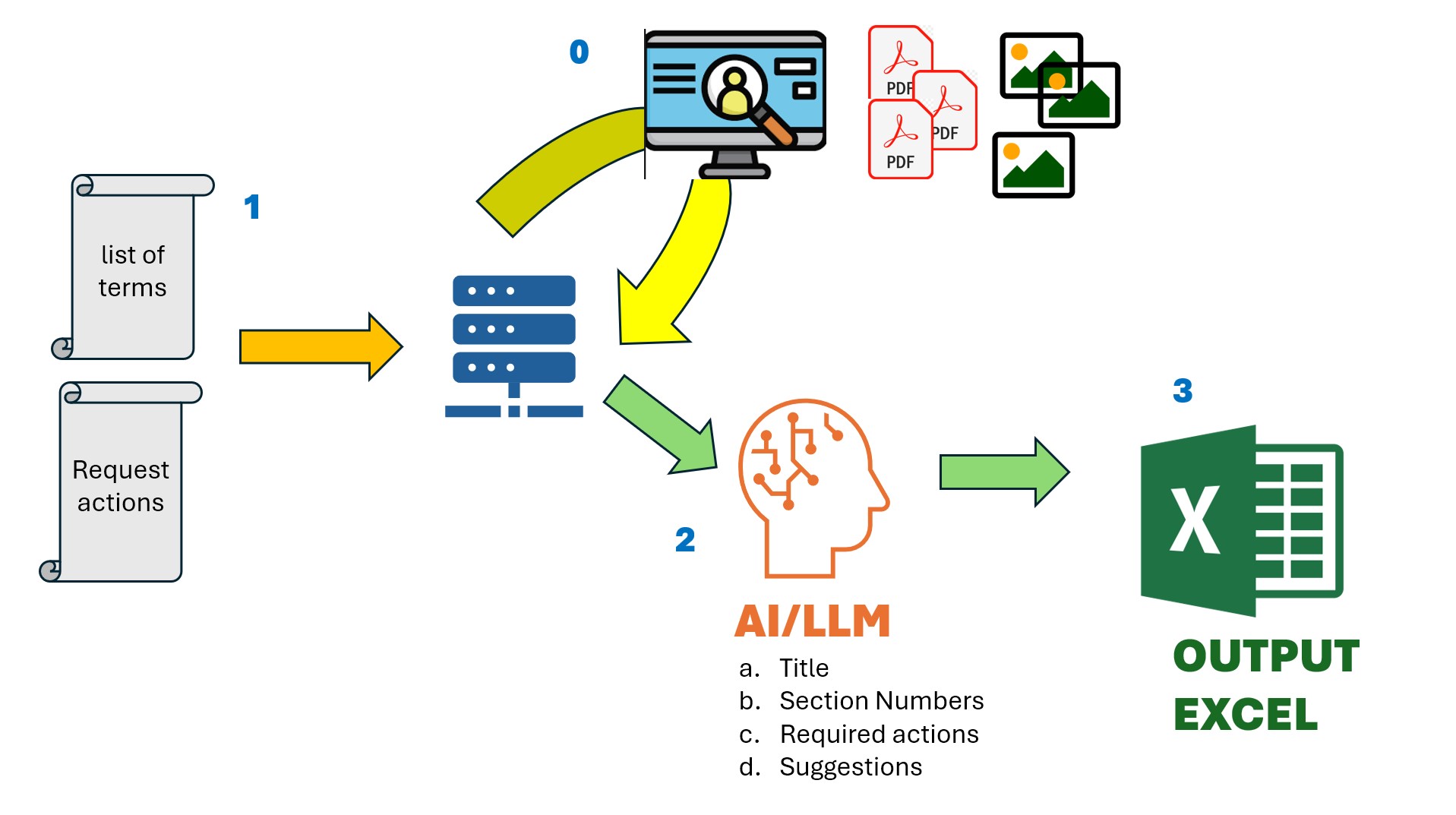
- Integrated the Gemini LLM model to extract specific details, such as title, section, and page number, from 500 PDF files into a single Excel report, based on user-selected keywords. - Tested six Hugging Face LLM models and selected the one best suited to extract specific Zoning District Schedule data, such as land type categorization, land usage, building type, area, building height, and over 40 other metrics, using fine-tuned prompts. - Effectively used OCR tools to extract text from images and employed an AI model to interpret the meaning, saving the results as a keyword-searchable resource. - Used the Python Beautiful Soup 4 package to scrape consistently updated PDF by-law or regulation files from the internet and created an updating module to track files requiring changes. - Developed a Next.js SSR frontend for users to generate Excel reports based on keywords, providing real-time updates on the time-consuming report generation progress and alerts for any backend issues. - Used the Python Flask framework to handle API requests with an object-oriented programming structure for LLM implementation.CHALLENGES
Low-cost LLM usage
- The client's budget for using the Gemini LLM model was limited, preventing us from sending all 500+ documents to the Gemini API for every report generation. Our solution involved pre-training the data once for the entire document set, categorizing and indexing all possible data results. This provided a ready-to-use result based on user-provided keywords.Limited Hugging Face model capabilities
- Finding a model that could effectively locate the precise numeric data proved challenging. Five of the six free models from Microsoft or Meta were insufficient. The chosen model required seven categories of prompts, totalling over 100 lines of prompt sentences, to produce reasonable results.Local application deployment request
- Late in the project, we learned the client couldn't host the system on a cloud server. We needed a quick solution to package the project. Using PyInstaller, we created a standalone application and wrote automated scripts for the local build process. The client received a zip file they could use to install the application themselves.